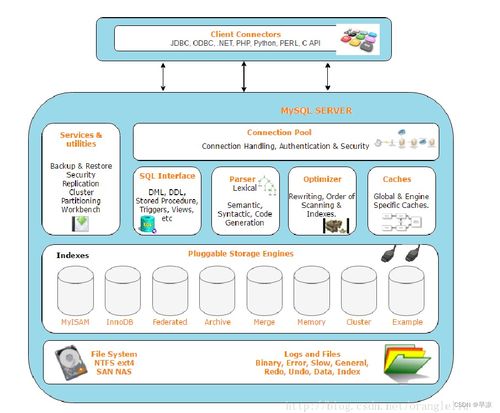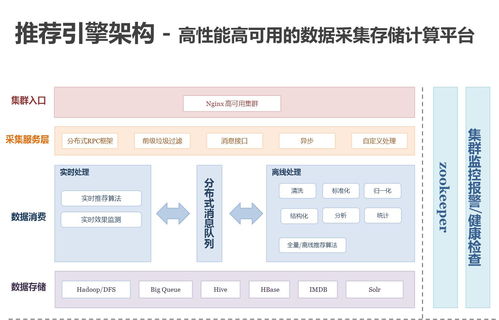
百分點作為大數據與人工智能領域的領先企業,其億級個性化推薦系統的發展歷程反映了從早期簡單規則引擎到當前智能、實時、可擴展系統的演變。系統的發展可以劃分為三個階段:初始階段(2010-2013年),基于用戶基本行為和規則進行推薦,注重數據處理的基礎構建;成長階段(2014-2017年),引入機器學習和協同過濾算法,逐步集成實時數據流處理;成熟階段(2018年至今),采用深度學習和多模態數據融合,支持億級用戶的高并發、低延遲推薦。這一歷程得益于數據處理技術的飛速發展,包括大數據框架如Hadoop和Spark的應用,以及云原生架構的采用。
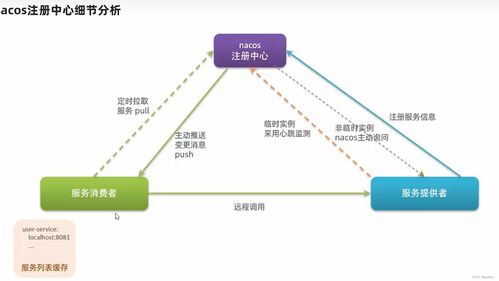
在實踐架構方面,百分點的推薦系統采用模塊化、分層設計,確保高可用性和彈性擴展。整體架構主要包括數據采集層、數據處理層、算法層、服務層和應用層。數據采集層負責從多渠道(如Web、移動端)收集用戶行為數據,使用日志收集工具如Flume和Kafka實現實時數據傳輸。數據處理層是關鍵支撐,涵蓋批處理和流處理兩部分:批處理使用Hadoop和Spark進行歷史數據清洗和特征工程,生成用戶畫像和物品特征;流處理借助Flink或Spark Streaming處理實時事件,如點擊和瀏覽行為,以快速更新推薦模型。存儲支持服務采用混合方案,包括HDFS用于大數據存儲,Redis和Cassandra用于緩存和實時數據查詢,以及Elasticsearch支持快速檢索,確保數據的高效訪問和持久化。
算法層是系統的核心,集成多種推薦算法,如協同過濾、基于內容的推薦和深度學習模型(例如神經網絡和強化學習),通過A/B測試框架優化模型性能。服務層通過微服務架構暴露API,使用Docker和Kubernetes進行容器化部署,實現負載均衡和自動擴縮容,保障系統在高并發場景下的穩定性。應用層則為最終用戶提供個性化推薦界面,集成到電商、媒體等業務平臺中。
百分點的億級個性化推薦系統通過演進式的技術迭代和穩健的架構設計,實現了高效的數據處理與存儲支持,這不僅提升了用戶體驗,也為企業提供了可擴展的解決方案。未來,隨著AI技術的進步,系統將進一步融合多源數據并強化實時智能,以應對更復雜的業務需求。