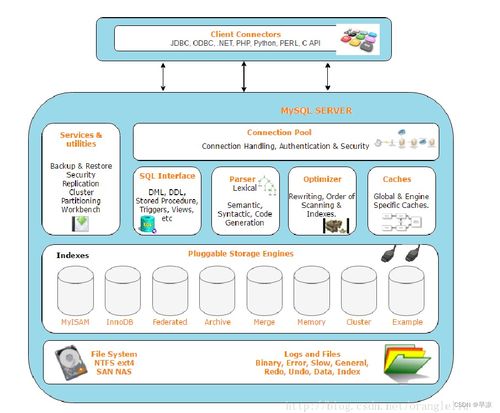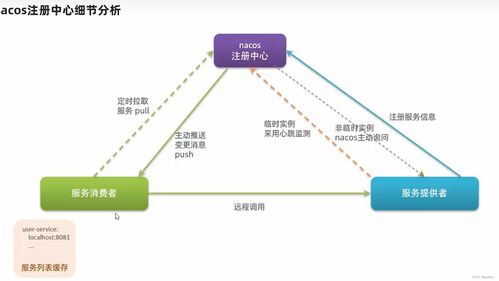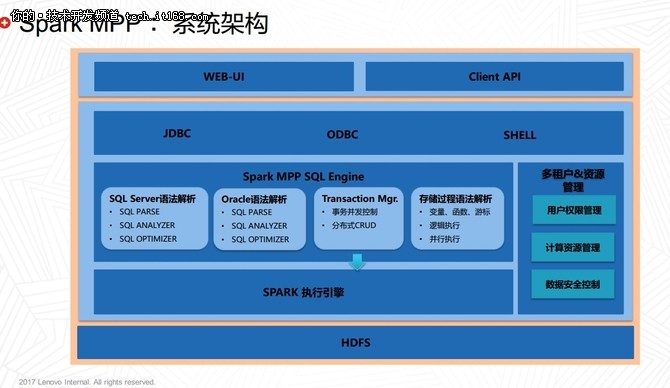
在當今大數據時代,企業對數據處理能力的需求日益增長,尤其是在高并發、實時分析場景下。Apache Spark作為主流的大數據處理引擎,以其內存計算和通用性廣受青睞。在面對大規模并行處理(MPP)場景時,Spark的默認架構可能面臨擴展性和性能瓶頸。本文探討如何擴展Spark引擎以支持MPP計算場景,并聚焦數據處理和存儲支持服務的優化策略。
理解MPP場景的核心需求是關鍵。MPP系統強調分布式計算節點間的并行協作,以處理海量數據查詢和分析任務。Spark引擎通過其彈性分布式數據集(RDD)和DataFrame API提供了良好的基礎,但原生Spark在跨節點數據交換和資源管理上可能不夠高效。為此,擴展Spark需要從以下幾個方面入手:
- 架構優化:引入MPP-aware的調度器,優化任務分配以減少數據傾斜。通過集成類似Apache Mesos或Kubernetes的資源管理器,實現動態資源分配,確保節點間負載均衡。利用Spark 3.0的Adaptive Query Execution特性,可以自動調整執行計劃以適應MPP場景。
- 數據處理增強:在數據處理層,擴展Spark以支持更高效的并行算法。例如,通過自定義數據源API,集成列式存儲格式如Apache Parquet或ORC,提升I/O性能。采用向量化執行引擎,減少函數調用開銷,這在MPP查詢中能顯著提升吞吐量。開發者可以構建用戶定義函數(UDF)和聚合器,以處理復雜邏輯,同時確保數據分區策略與MPP需求對齊。
- 存儲支持服務:存儲是MPP場景的基石。擴展Spark時,需要優化與分布式文件系統(如HDFS)或對象存儲(如AWS S3)的集成。通過緩存機制(如Alluxio)減少數據讀取延遲,并實現數據本地化策略。支持事務性存儲(如Delta Lake)可以確保數據一致性,這對于實時MPP分析至關重要。在服務層面,提供監控和自動化工具,幫助運維團隊管理存儲資源,預防瓶頸。
- 性能調優與案例:在實際部署中,通過基準測試驗證擴展效果。例如,某金融公司通過擴展Spark引擎,在MPP場景下處理TB級交易數據時,查詢響應時間降低了50%。關鍵在于調整Spark配置參數(如executor內存、并行度),并結合硬件加速(如GPU)。IT168技術開發專區強調,這種擴展不僅提升了計算效率,還降低了總體擁有成本(TCO)。
擴展Spark引擎支持MPP計算場景是一個系統工程,涉及架構、數據處理和存儲服務的全方位優化。隨著數據量持續增長,這種擴展將幫助企業構建更敏捷的數據平臺。結合AI驅動的自動化優化,Spark在MPP領域的應用前景廣闊。開發者應持續關注社區動態,如Spark與云原生技術的融合,以保持技術領先。