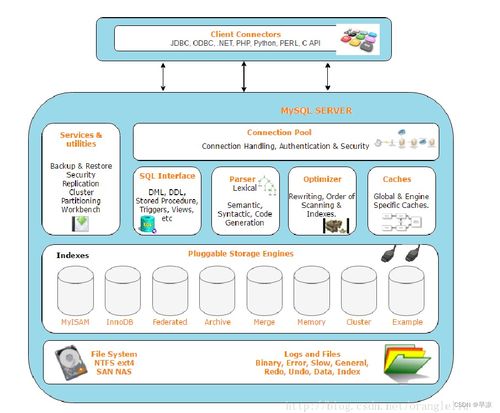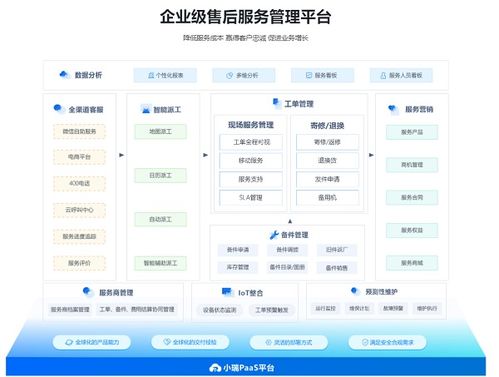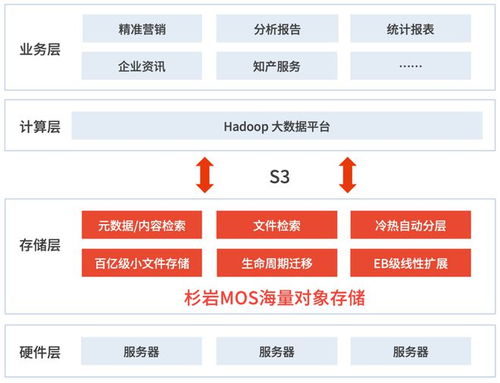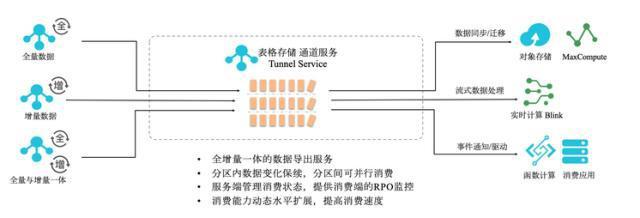
隨著企業(yè)數(shù)字化轉(zhuǎn)型的深入,數(shù)據(jù)中臺(tái)作為企業(yè)數(shù)據(jù)能力的核心載體,其結(jié)構(gòu)化大數(shù)據(jù)的存儲(chǔ)設(shè)計(jì)與處理支撐服務(wù)成為關(guān)鍵。本文將從結(jié)構(gòu)化大數(shù)據(jù)的特點(diǎn)出發(fā),探討存儲(chǔ)架構(gòu)的設(shè)計(jì)原則、技術(shù)選型及數(shù)據(jù)處理服務(wù)的支撐機(jī)制。
一、結(jié)構(gòu)化大數(shù)據(jù)的特點(diǎn)與存儲(chǔ)挑戰(zhàn)
結(jié)構(gòu)化大數(shù)據(jù)通常指具有明確定義模式的海量數(shù)據(jù),如交易記錄、用戶信息、日志數(shù)據(jù)等。其特點(diǎn)包括數(shù)據(jù)量龐大、讀寫(xiě)頻繁、schema相對(duì)固定但可能演進(jìn)。存儲(chǔ)設(shè)計(jì)需應(yīng)對(duì)高并發(fā)、低延遲、水平擴(kuò)展及數(shù)據(jù)一致性等挑戰(zhàn)。
二、存儲(chǔ)架構(gòu)設(shè)計(jì)原則
- 分層存儲(chǔ):根據(jù)數(shù)據(jù)熱度和訪問(wèn)頻率,采用多級(jí)存儲(chǔ)策略,如熱數(shù)據(jù)存于內(nèi)存或SSD,冷數(shù)據(jù)存于HDD或?qū)ο蟠鎯?chǔ)。
- 分布式架構(gòu):利用分布式數(shù)據(jù)庫(kù)或數(shù)據(jù)倉(cāng)庫(kù)(如ClickHouse、Apache Doris)實(shí)現(xiàn)水平擴(kuò)展,支持PB級(jí)數(shù)據(jù)存儲(chǔ)。
- Schema管理:支持靈活的schema演進(jìn),通過(guò)Avro、Protobuf等格式保障數(shù)據(jù)兼容性。
- 數(shù)據(jù)分區(qū)與索引:按時(shí)間、業(yè)務(wù)鍵分區(qū),結(jié)合二級(jí)索引提升查詢效率。
三、技術(shù)選型與實(shí)踐
- 在線事務(wù)處理(OLTP):可選NewSQL數(shù)據(jù)庫(kù)(如TiDB、CockroachDB)或傳統(tǒng)關(guān)系型數(shù)據(jù)庫(kù)分庫(kù)分表。
- 在線分析處理(OLAP):采用列式存儲(chǔ)數(shù)據(jù)庫(kù)(如ClickHouse、Apache Druid)或數(shù)據(jù)湖架構(gòu)(如Iceberg、Hudi)。
- 存儲(chǔ)引擎優(yōu)化:結(jié)合壓縮算法(如ZSTD)、編碼技術(shù)減少存儲(chǔ)空間,提升I/O性能。
四、數(shù)據(jù)處理與存儲(chǔ)支撐服務(wù)
- 數(shù)據(jù)集成服務(wù):通過(guò)CDC(Change Data Capture)、ETL工具實(shí)現(xiàn)多源數(shù)據(jù)實(shí)時(shí)同步與批量導(dǎo)入。
- 計(jì)算引擎支撐:集成Spark、Flink等計(jì)算框架,支持流批一體處理,滿足實(shí)時(shí)分析與離線挖掘需求。
- 數(shù)據(jù)治理與元管理:建立數(shù)據(jù)目錄、血緣追蹤、質(zhì)量監(jiān)控體系,保障數(shù)據(jù)可信可用。
- 服務(wù)化接口:提供RESTful API、SQL查詢接口,降低業(yè)務(wù)方使用門(mén)檻,促進(jìn)數(shù)據(jù)賦能。
五、總結(jié)與展望
結(jié)構(gòu)化大數(shù)據(jù)存儲(chǔ)設(shè)計(jì)需平衡性能、成本與易用性,而數(shù)據(jù)處理支撐服務(wù)則需實(shí)現(xiàn)數(shù)據(jù)從采集到消費(fèi)的全鏈路管理。隨著云原生、AI增強(qiáng)管理技術(shù)的發(fā)展,數(shù)據(jù)中臺(tái)存儲(chǔ)與處理服務(wù)將更加智能化、自動(dòng)化,成為企業(yè)數(shù)據(jù)驅(qū)動(dòng)決策的堅(jiān)實(shí)基石。