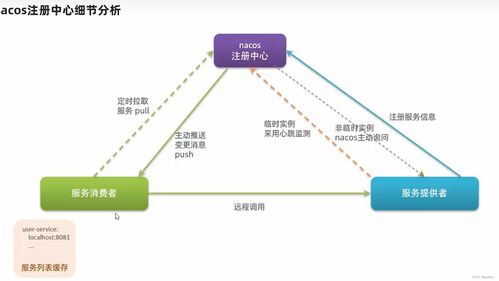
在數字時代,個性化推薦系統已成為提升用戶體驗和商業價值的關鍵技術。百分點作為國內領先的數據智能公司,其億級個性化推薦系統經歷了多年的演進與發展。本文將回顧該系統的發展歷程,并深入闡述其實踐架構中數據處理與存儲支持服務的核心設計。
一、發展歷程:從初步探索到規模化應用
百分點推薦系統的發展可分為三個階段:初期探索階段(2010-2013年)、技術優化階段(2014-2017年)和規模化應用階段(2018年至今)。在初期,系統主要依賴簡單的協同過濾和基于內容的推薦算法,處理百萬級用戶數據,旨在驗證推薦對業務轉化的效果。隨著大數據技術的興起,百分點在技術優化階段引入了實時計算和深度學習模型,提升了推薦的準確性和實時性,用戶規模擴展至千萬級。進入規模化應用階段后,系統全面支持億級用戶和數十億物品的推薦場景,結合多源異構數據(如行為日志、社交網絡和業務數據),實現了高精度、低延遲的個性化服務,覆蓋電商、媒體、金融等多個行業。
二、實踐架構:數據處理與存儲支持服務
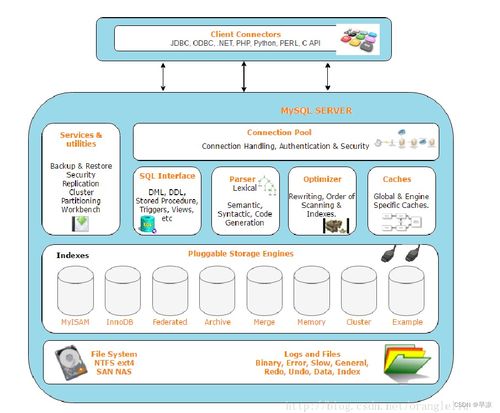
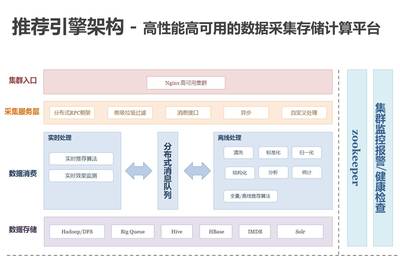
百分點億級推薦系統的架構以數據處理和存儲為核心,確保系統的高可用性、可擴展性和實時性。整體架構分為數據采集層、數據處理層、存儲層和服務層。
- 數據采集層:系統通過日志采集工具(如Flume和Kafka)實時收集用戶行為數據、物品元數據和上下文信息。這些數據源包括點擊流、搜索記錄、交易數據等,確保數據完整性和低延遲傳輸。
- 數據處理層:該層采用批處理和流處理相結合的Lambda架構。批處理部分使用Spark和Hadoop進行離線計算,構建用戶畫像、物品特征和全局模型;流處理部分則依賴Flink和Storm實現實時特征提取和模型更新,例如實時調整用戶興趣權重。通過機器學習平臺集成多種算法(如矩陣分解、深度學習),系統能夠動態優化推薦策略。
- 存儲層:為支撐億級數據的快速訪問,存儲服務采用混合存儲方案。HDFS和HBase用于存儲歷史數據和模型參數,保障離線計算的穩定性;Redis和Cassandra作為緩存和實時存儲,加速在線推薦查詢;引入Elasticsearch支持復雜的多維度檢索。這種分層存儲設計不僅提高了數據讀寫效率,還實現了數據冗余和容災備份。
- 服務層:基于微服務架構,推薦服務通過RESTful API對外提供,結合負載均衡和分布式調度,確保高并發下的穩定響應。服務層還集成了A/B測試和監控系統,實時評估推薦效果并動態調整參數。
三、總結與展望
百分點億級個性化推薦系統通過不斷迭代,在數據處理和存儲支持方面積累了豐富經驗,實現了從數據采集到實時服務的全鏈路優化。隨著AI技術和5G網絡的普及,系統將進一步融合多模態數據(如圖像、語音),強化聯邦學習和可解釋性推薦,以應對更復雜的業務場景。這一實踐不僅為行業提供了參考,也彰顯了數據驅動決策在智能化轉型中的核心價值。