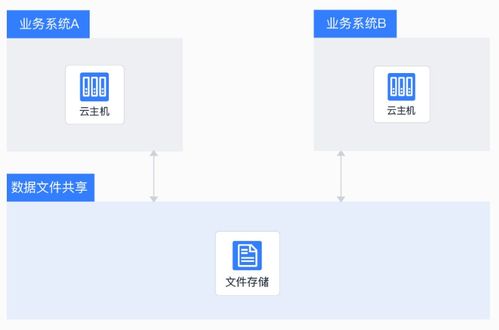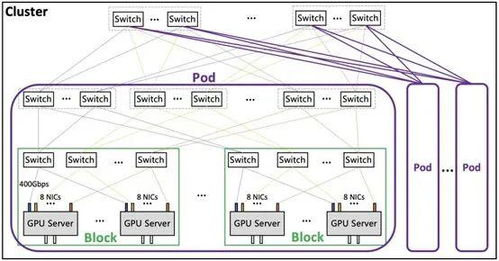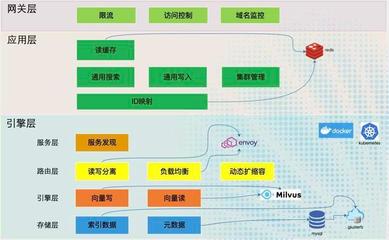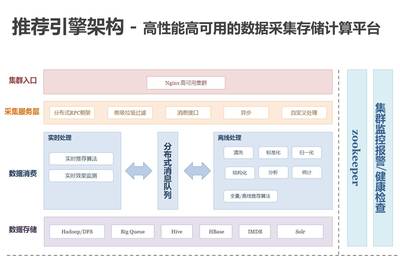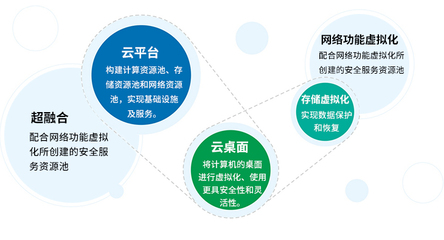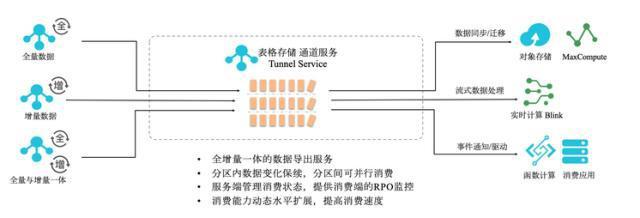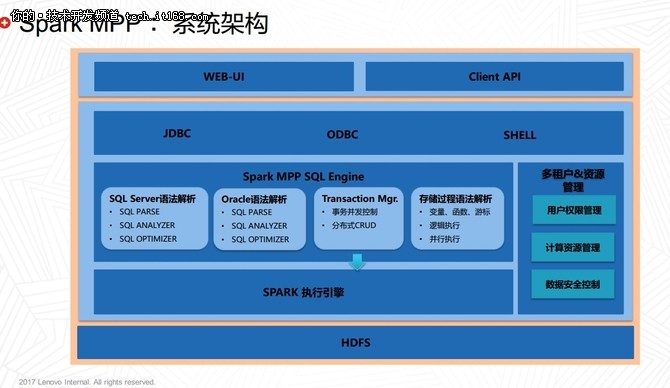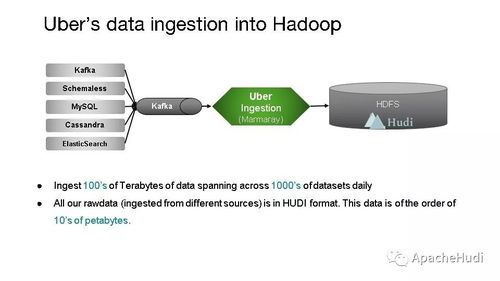
隨著大數(shù)據(jù)時代的到來,企業(yè)對數(shù)據(jù)處理和分析的需求日益復雜,既需要支持傳統(tǒng)的批處理任務,又要求能夠進行近實時分析,以快速響應業(yè)務變化。Apache Hudi(Hadoop Upserts, Deletes & Incrementals)作為一種開源數(shù)據(jù)湖解決方案,通過統(tǒng)一的存儲和服務層,成功解決了批處理和近實時分析之間的鴻溝,為現(xiàn)代數(shù)據(jù)架構(gòu)提供了強大的支持。
Hudi 的核心優(yōu)勢在于其統(tǒng)一的數(shù)據(jù)存儲和處理能力。它構(gòu)建在 Hadoop 兼容的存儲系統(tǒng)之上,如 HDFS 或云存儲(例如 AWS S3),允許用戶在同一數(shù)據(jù)湖中同時進行批處理(如每日 ETL 作業(yè))和近實時分析(如流式數(shù)據(jù)攝取和查詢)。通過引入 Upsert(更新插入)和增量處理機制,Hudi 高效地管理數(shù)據(jù)變更,避免了傳統(tǒng)批處理中常見的全表重寫問題,從而降低了存儲成本并提高了處理效率。
在數(shù)據(jù)處理方面,Hudi 支持多種數(shù)據(jù)服務模式。例如,它提供了兩種表類型:Copy-on-Write(寫時復制)和 Merge-on-Read(讀時合并)。Copy-on-Write 表適用于寫操作較少的場景,通過直接在寫入時更新數(shù)據(jù)文件來保證查詢性能;而 Merge-on-Read 表則更適合高頻率的寫入場景,它將更新延遲到讀取時合并,從而優(yōu)化寫入吞吐量,非常適合近實時數(shù)據(jù)流處理。這種靈活性使得 Hudi 能夠適應不同業(yè)務需求,無論是歷史數(shù)據(jù)分析還是實時監(jiān)控。
對于存儲支持服務,Hudi 集成了多種大數(shù)據(jù)生態(tài)系統(tǒng)組件,如 Apache Spark、Apache Flink 和 Presto/Trino,提供了無縫的數(shù)據(jù)攝取、轉(zhuǎn)換和查詢體驗。用戶可以利用 Hudi 的增量拉取功能,僅處理自上次處理以來的新數(shù)據(jù),這大大減少了計算資源消耗,并加速了數(shù)據(jù)管道。Hudi 還支持事務性保證和數(shù)據(jù)版本管理,確保數(shù)據(jù)的一致性和可追溯性,這對于企業(yè)級應用至關(guān)重要。
實際應用中,許多公司已將 Hudi 部署在生產(chǎn)環(huán)境中,用于統(tǒng)一處理批量和流式數(shù)據(jù)。例如,在電商平臺中,Hudi 可以同時處理歷史訂單的批分析(如月度銷售報告)和實時訂單流的近實時查詢(如庫存監(jiān)控),實現(xiàn)了數(shù)據(jù)存儲和服務的統(tǒng)一。這不僅簡化了數(shù)據(jù)架構(gòu),還提升了整體數(shù)據(jù)處理的敏捷性和效率。
總而言之,Apache Hudi 通過其創(chuàng)新的存儲設(shè)計和數(shù)據(jù)處理服務,成功將批處理和近實時分析融合在一起。它降低了數(shù)據(jù)湖的維護復雜度,同時提供了高性能和可擴展性,是企業(yè)構(gòu)建現(xiàn)代化數(shù)據(jù)平臺的理想選擇。隨著數(shù)據(jù)需求的不斷演進,Hudi 將繼續(xù)在統(tǒng)一數(shù)據(jù)處理領(lǐng)域發(fā)揮關(guān)鍵作用,助力企業(yè)實現(xiàn)更智能的數(shù)據(jù)驅(qū)動決策。